Site menu:

cNORM - Datenaufbereitung
Inhalt
- Repräsentativität der Datenbasis
- Gewichtung bei Verstößen gegen die Repräsentativität
- Wahl der Stichprobengröße
- Datenaufbereitung in R
Repräsentativität der Datenbasis
Der Ausgangspunkt einer Normierung sollte immer eine repräsentative Stichprobe sein. Die Herstellung der Repräsentativität ist eine der schwierigsten Aufgaben der Testkonstruktion und muss deshalb mit entsprechender Sorgfalt durchgeführt werden. Dabei ist es zunächst wichtig, diejenigen Variablen zu identifizieren, die systematisch mit der zu messenden Variable kovariieren. Bei Schulleistungs- und Intelligenztests sind dies in Deutschland beispielsweise die Schulform, das Bundesland, der sozioökonomische Hintergrund usw. Achtung: Die Vergrößerung einer Stichprobe nützt der Normierungssicherheit nur dann, wenn die genannten Variablen hierdurch nicht systematisch verzerrt bleiben oder verzerrt werden. So wäre es beispielsweise bei der Erhebung von Schulleistungstests nutzlos oder sogar kontraproduktiv, die Stichprobe weiter zu vergrößern, wenn die Stichprobe nur an einer einzigen Schulform oder nur in einem einzigen Bundesland erhoben wird.
Der Vorteil von kontinuierlicher Normierung liegt in der generell niedrigen erforderlichen Stichprobengröße (ca. 100 pro Jahrgang oder Klassenstufe). Eine Möglichkeit, Repräsentativität herzustellen, besteht deshalb darin, aus überrepräsentierten Strata so viele zufällig ausgewählte Fälle zu löschen, bis die einzelnen Strata mit dem erforderlichen Prozentsatz in der Gesamtstichprobe repräsentiert sind. Allerdings gehen hierdurch mühsam erhobene Daten wieder verloren.
Gewichtung
Falls sich Repräsentativität nicht durch das Entfernen von Fällen nicht erreichen lassen, so besteht eine zweite Möglichkeit darin, die Daten mittels Iterative Proportional Fitting (Raking) zu gewichten. In Simulationsstudien (Gary et al., 2023, 204) konnten wir zeigen, dass Gewichtungen meistens zu besseren Normen führen. Allerdings haben wir diese Simulationsstudien bislang nur mit der verteilungsfreien kontinuierlichen Normierungsmethode durchgeführt, die in cNORM implementiert ist. Probleme der Gewichtung ergaben sich nur dann, wenn die Varianz in der Normierungsstichprobe stark von der tatsächlichen Varianz in der Vergleichspopulation abwich. Achten Sie also bei der Anwendung von Gewichtung darauf, dass keine zu starken Abweichungen von der Repräsentativität kompensiert werden müssen und dass Bevölkerungsgruppen, deren Testergebnisse relativ stark vom Populationsmittel abweichen, bereits bei der Datenerhebung ausreichend berücksichtigt werden.
Wahl der Stichprobengröße
Die Größe der notwendigen Stichprobe kann nicht allgemein verbindlich beziffert werden, sondern richtet sich danach, wie gut der Test (bzw. die Skala) in den Extrembereichen differenzieren muss.
In Deutschland ist es beispielsweise üblich (wenn auch längst nicht immer sinnvoll), bei der Auswahl der geeigneten Schulform zwischen IQ < 70 (Förderschwerpunkt geistige Entwicklung) und IQ > 70
(Förderschwerpunkt Lernen) zu differenzieren. Ein IQ-Test, der für die Schulplatzierung eingesetzt wird, muss also in der Lage sein, eine Abweichung von 2 SD vom Mittelwert noch möglichst
präzise abzubilden. Geht es hingegen um die Diagnose einer Lese-Rechtschreibstörung, dann reicht im Allgemeinen bereits eine Abweichung von 1,5 SD vom Populationsmittelwert für die Diagnose
aus. Als Daumenregel für die Ermittlung der idealen Stichprobengröße lässt sich festhalten, dass die Normierungsunsicherheit vor allem in denjenigen Leistungsbereichen zunimmt, die nur noch mit
geringer Wahrscheinlichkeit in der Normierungsstichprobe vertreten sind. (Dies gilt übrigens nicht nur für kontinuierliche Normierung, sondern für alle Normierungsverfahren.)
So beträgt beispielsweise die Wahrscheinlichkeit, dass in einer repräsentativen Zufallsstichprobe von N = 100 kein einziges Kind einen IQ unter 70 aufweist, etwa 10%. Bei einer Stichprobengröße von
N = 200 sinkt diese Wahrscheinlichkeit auf 1 %. Die Verdopplung der Stichprobengröße trägt in diesem Bereich also stark zur Erhöhung der Normierungssicherheit bei.
Da kontinuierliche Normierung immer auf die gesamte Stichprobe zurück greift, erhöht sich damit die statistische Power der Normwertanpassung in jedem einzelnen Altersbereich. In der Folge können die Normstichproben deutlich reduziert
werden. Mit einer Stichprobengröße von n = 100 pro Jahrgang oder Klassenstufe erreichen die Normen bereits eine Anpassungsgüte, die bei konventioneller Normierung erst mit Stichprobengrößen
von n = 400 und mehr erreicht werden (W. Lenhard & Lenhard, 2021). Die Normen werden also insgesamt nicht nur präziser, sondern die Normierungsprojekte insgesamt auch kostengünstiger.
Datenaufbereitung in R
Wenn eine repräsentative Stichprobe in ausreichender Größe hergestellt wurde, dann müssen die Daten zunächst eingelesen werden. Fälle mit Missings in relevanten Variablen werden bei cNORM aus der Datenanalyse ausgeschlossen. Für eine kontinuierliche Normierung benötigt man neben der Variable mit den Rohwerten eine explanatorische Variable (z. B. Alter oder Beschulungsdauer), die als diskrete Gruppierungsvariable oder als kontinuierliche Variable vorliegen kann. Achten Sie bei der diskreten Gruppierungsvariable bitte darauf, dass es sich hierbei um eine numerische Variable handeln muss, bei der als Variablenwert für die einzelnen Gruppen jeweils der Gruppenmittelwert der entsprechenden kontinuierlichen Variablen verwendet wird, also z. B. 10,5 für alle Kinder zwischen 10 und 11 Jahren. Wenn bei der Modellierung mit Taylor-Polynomen (d. h. der verteilungsfreien Methode) zunächst nur eine kontinuierliche Variable zur Verfügung steht, dann muss diese zusätzlich in eine diskrete Gruppierungsvariable umkodiert werden. Die Methode ist allerdings relativ robust gegenüber Veränderungen in der Granularität der Gruppenunterteilung. So hängt das Ergebnis der Normierung beispielsweise kaum davon ab, ob man Halbjahres- oder Ganzjahresabstufungen wählt (siehe A. Lenhard, Lenhard, Suggate & Segerer, 2016). Je stärker der Verlauf der Rohwerte über die explanatorische Variable hinweg von einer linearen Entwicklung abweicht, desto feinstufiger sollten die Gruppen gebildet werden. Bei parametrischer Modellierung mit der Beta-Binomialverteilung ist eine zusätzliche Gruppenaufteilung generell unnötig.
Wenn die kontinuierliche explanatorische Variable in eine Gruppenvariable umkodiert werden muss, dann kann auf die folgende Hilfsfunktion zurückgegriffen werden:
# Generiert aus der kontinuierlichen Altersvariablen 'age' des
# ppvt-Datensatzes eine diskrete Gruppenvariable.
# Im Beispiel werden 12 äquidistanten Gruppen generiert.
group <- getGroups(ppvt$age, 12)
Bei Verwendung von RStudio lassen sich Daten bequem über die Import-Funktion aus anderen Statistik-Umgebungen einlesen:
Für Demonstrationszwecke enthält cNORM bereits einen bereinigten Datensatz, welcher einem ehemaligen Normierungsprojekt entstammt (ELFE 1-6, W. Lenhard & Schneider, 2006, Untertest Satzverständnis) und den wir in der Folge zur Demonstration des Packages verwenden. Ein weiterer großer (aber nicht repräsentativer) Datensatz, den wir zur Demonstration verwenden, basiert auf einem ins Deutsche adaptierten Wortschatztest (PPVT-4, A. Lenhard, Lenhard, Segerer & Suggate, 2015). Darüber hinaus enthält cNORM einen großen Datensatz des CDC mit physiologischen bzw. biometrischen Daten (Körpergröße, Gewicht und BMI) von über 45.000 Kindern und Jugendlichen zwischen 2 und 25 aus den USA (CDC, 2012). Informationen über die Datensätze erhalten Sie, indem Sie ?elfe, ?ppvt oder ?CDC eingeben.
# Lädt das Package cNorm
library(cNORM)
# Zeigt eine Beschreibung des ELFE-Datensatzes an
?elfe
# Zeigt die ersten Reihen des Datensatzes
head(elfe)
Wie man sieht, existiert im Datensatz 'elfe' gar keine Altersvariable, sondern nur eine Personen-ID, ein Rohwert und eine Gruppierungsvariable. Die Gruppierungsvariable dient in diesem Fall gleichzeitig als kontinuierliche explanatorische Variable, da bei der Testnormierung Kinder nur ganz zu Beginn und in der Mitte des Schuljahres untersucht wurden. Der Wert 2.0 bedeutet beispielsweise, dass sich die Kinder zu Beginn des 2. Schuljahres befanden, der Wert 2.5 heißt, dass die Kinder in der Mitte des 2. Schuljahres untersucht wurden. Man könnte bei der Durchführung einer Normierung aber beispielsweise auch Kinder gleichmäßig über das ganze Schuljahr hinweg untersuchen. Die Beschulungsdauer (z. B. in Wochen) ginge dann als kontinuierliche explanatorische Variable ein, in der Gruppierungsvariable könnte jeweils die erste und die zweite Hälfte jedes Schuljahres zu einer Gruppe zusammengefasst werden.
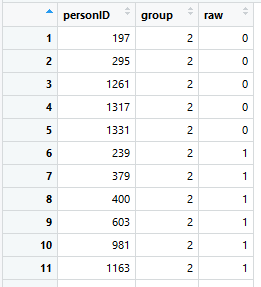
Im 'elfe'-Datensatz gibt es sieben Gruppen mit jeweils 200 Fällen, ingesamt also 1400 Fälle:
# Deskriptive Ergebnisse ausgeben
by(elfe$raw, elfe$group, summary)
 |
Installation |
Gewichtung |
 |