Site menu:

cNORM - Troubleshooting und Frequently Asked Questions
cNORM funktioniert in vielen Anwendungsszenarien "out of the box", v. a. bei einer hinreichend großen Datenmenge und einer genügend großen Varianzaufklärung der explanatorischen Variablen (also beispielsweise einem deutlichen Alterstrend). Es gibt jedoch auch Fälle, die schwieriger zu handhaben sind. Wir raten in jedem Fall dazu, die generierten Lösungen auf Plausibilität zu prüfen und die Parameter falls nötig "manuell" nachzujustieren. Ähnlich wie bei Faktorenanalysen ist die Modellauswahl ein mehrstufiger Prozess, bei dem i. d. R. verschiedene Modelle durchgerechnet und hinsichtlich unterschiedlicher Gütekriterien miteinander verglichen werden müssen. Im Fall von cNorm gibt es vor allem drei Gütekriterien, nämlich die Varianzaufklärung, die Einfachheit des Modells sowie die Modellplausiblität bzw. -konsistenz. Letztere muss in der Regel vor allem an den Modellrändern beachtet werden.
Kurz zusammengefasst:
- Ein Powerparameter von k = 4 ist für fast alle Anwendungszwecke ausreichend.
- Modelle mit einer geringen Anzahl an Termen (z. B. 'terms = 4' bis 'terms = 10' in 'bestModel') sind am robustesten und sie erbringen in Kreuzvalidierungen in der Regel die besten Ergebnisse. Vermeiden Sie Modelle mit vielen Termen und nehmen Sie stattdessen lieber ein etwas geringeres R2 in Kauf.
- Inspizieren Sie nach einer ersten Modellberechnung die Informationsfunktionen der Modelle ('plotSubset') und die Perzentillinien ('plotPercentiles' und 'plotPercentileSeries'). Berechnen sie in einem zweiten Schritt noch einmal das Modell mit denjenigen Parametern (also z. B. einer bestimmten Anzahl an Termen bei gegebenem k), die Sie zuvor als optimal bestimmt haben.
- Bei einem Datensatz mit vielen fein abgestuften Altersgruppen mit kleinen Stichproben kann es günstiger sein, die Altersgruppen zu breiteren Intervallen zusammenzulegen.
1. Perzentillinien überschneiden sich
Bei der Modellierung kann es v. a. in den Extrembereichen, bei starken Boden- oder Deckeneffekten oder im Fall einer Überanpassung zu inkonsistenten Modellen kommen. Diese äußern sich beispielsweise darin, dass sich die Linien der Perzentile überschneiden ('plotPercentiles') oder dass in der Modellierung eine entsprechende Warnung ausgegeben wird ('checkConsistency').
Mögliche Lösungen:
- Variieren Sie die Anzahl an Termen des Modells (Parameter 'terms' in der Funktion 'bestModel').
- Nutzen Sie Kreuzvalidierung ('cnorm.cv') und Darstellungen der Informationsfunktion ('plotSubset') um eine sinnvolle Anzahl an Parametern zu ermitteln, die anschließend in der Modellierung eingesetzt werden kann.
- Reduzieren Sie die Anzahl der Terme. Einfachere Modelle führen zu glatteren Linien. Vermeiden Sie wellige Verläufe, da diese auf eine Überanpassung hinweisen.
- Verwenden Sie die Funktion 'plotPercentileSeries' um eine Serie an Modellen zu plotten. Geben Sie dabei mit dem Parameter 'end' die maximale Anzahl an Termen an.
- Beachten Sie, dass im Prinzip jedes Modell nur einen endlichen Bereich hat, innerhalb dessen es konsistente Ergebnisse liefert. Überlegen Sie also, welchen Normwertbereich Sie überhaupt abdecken möchten. Überlegen Sie, ob Ihr Test überhaupt geeignet ist, diesen Bereich abzudecken, bzw. wo ggf. Decken- oder Bodeneffekte einsetzen. Beachten Sie, dass Normwerte nur für die konsistenten Modellbereiche berichtet werden sollten. Eventuell müssen inkonsistente Randbereiche also einfach abgeschnitten werden.
# Darstellung der Perzentile
plotPercentiles(data, model) # Darstellung des aktuellen Modells
plotPercentileSeries(data, model) # Darstellung einer Reihe an Modellen
2. Umgang mit Kovariaten
Die Frage, ob man für verschiedene Personengruppen einer Population (z. B. Männer versus Frauen, Personen mit hoher versus niedriger Bildung ...) getrennte Normen generieren sollte, geht über die rein statistische Modellierbarkeit der Daten hinaus. Bitte überlegen Sie, ob eine solche Unterscheidung für Ihren Anwendungszweck überhaupt sinnvoll ist oder nicht.
Mögliche Lösungen:
- Stratifizieren Sie die Stichprobe vor der Modellierung anhand aller relevanten Variablen.
- Falls für eine binäre Variable (z. B. Geschlecht) unterschiedliche Normen notwendig sind: cNORM erfordert kleinere Stichproben als konventionelle Normierungstechniken (siehe Punkt 3). Der beste Weg besteht häufig darin, die Stichprobe in die einzelnen Teilstichproben aufzuteilen und diese getrennt zu modellieren.
- VORSICHT! EXPERIMENTELL! Seit Version 1.2.0 ist es möglich, eine binäre Kovariate mitzumodellieren. Wir können zum jetzigen Zeitpunkt noch nicht bewerten, ob unsere Algorithmen hierfür generell gute Lösungen ermitteln. Wenn Sie die Kovariate einbeziehen, so muss diese in der Datenaufbereitung mitgegeben und später bei der Generierung der Normen angegeben werden. Rückmeldungen über Erfolge bzw. Misserfolge sind aber jederzeit gerne willkommen.
# Einbezug einer Kovariaten am Beispiel der PPVT4-Daten
# (1 = Jungen, 2 = Mädchen)data1 <- rankByGroup(PPVT, group="group", raw="raw", covariate="sex")
data1 <- computePowers(data1)
model <- bestModel(data1)
plotPercentile(data1, model, covariate = 1) # Ausprägung der Kovariaten muss angegeben werden# Häufig setzen sich Kovariaten in der Modellierung nicht durch und
# werden aussortiert. Aufnahme der Kovariaten und aller Interaktionen
# in das Model erzwingen (was aber zu instabilen Modellen führen
# könnte):model <- bestModel(data1, force.in = c("COV", "L1COV", "A1COV", "L1A1COV"))
# Basierend auf Ihren theoretisch motivierten Erwartungen zum Einfluss der
# Kovariaten, können Sie auch spezifische Terme der Kovariaten spezifizieren,
# z. B. einen linearen Term und die Dreifachinteraktion:model <- bestModel(data1, force.in = c("COV", "L1A1COV"))
# Darstellung der Modelle nebeneinander:
c(plotPercentiles(data1, model, covariate = 1),
plotPercentiles(data1, model, covariate = 2))
3. Notwendige Fallzahl für Modellierungen
Unsere Simulationen weisen darauf hin, dass ab einer Gruppengröße von 50 Fällen pro Altersgruppe sehr reliable Modelle berechnet werden können (siehe Abbildung), vielleicht auch darunter. Wichtiger als eine besonders große Fallzahl ist bei cNorm, dass die Gesamtstichprobe möglichst repräsentativ ist. (Bitte beachten Sie, dass Stichproben mit steigender Fallzahl nicht automatisch repräsentativer werden!) Wird die Fallzahl allerdings zu klein gewählt, dann reduziert sich nicht nur die Power der angewandten statistischen Verfahren, sondern es wird auch schwierig, die Stichprobe hinsichtlich aller relevanten Merkmale zu stratifizieren. Zudem spielt auch die Anzahl an Altersgruppen und die Stärke des Einflusses der explanatorischen Variablen eine Rolle.
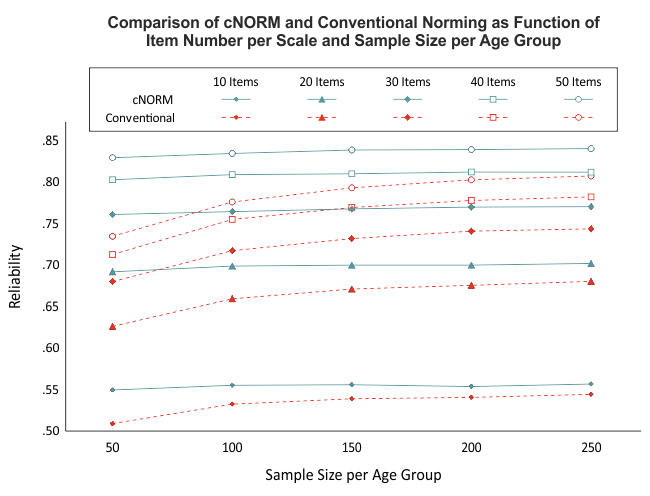
cNORM ist zwar in der Lage, kleinere Verletzungen der Repräsentativität oder geringe Fallzahlen in einzelnen Altersgruppen teilweise zu kompensieren, da die Modelle auf der Basis des gesamten Datensatzes berechnet werden. Dennoch sollte bei der Normierung eines Testverfahrens auf eine sehr hochwertige Datengrundlage geachtet werden.
Mögliche Lösung:
- Sollten Sie wenige Fälle in den einzelnen Altersgruppen haben, so fassen Sie die Daten lieber zu größeren Altersgruppen zusammen. Verwenden Sie z. B. trotz breiterem Altersbereich lieber vier Gruppen mit hinreichender Fallzahl als acht Gruppen mit nur kleiner Fallzahl. Die Mittelwerte der Altersgruppen müssen nicht unbedingt gleichabständig sein.
4. Geringe Varianzaufklärung der explantorischen Variablen
Seit Version 1.1.8 prüft cNORM in der Datenvorbereitung (Funktionen 'prepareData' und 'computePowers') automatisch mittels einer polynomialen Regression (bis zum Powerparameter k) den Anteil aufgeklärter Varianz durch die explanatorische Variable. Es werden also nicht nur lineare, sondern auch komplexere Zusammenhänge erfasst, üblicherweise bis zur vierten Potenz (Grundeinstellung). Liegt nur ein kleiner Zusammenhang zwischen der explanatorischen Variablen und den Rohwerten vor, so wirft cNORM eine Warnmeldung aus. Es stellt sich in diesem Fall die Frage, ob der Einbezug der explanatorischen Variablen in die Berechnung der Normen wirklich sinnvoll ist oder ob nicht beispielsweise eine einzelne Normtabelle ausreicht. Bei einer niedrigen Varianzaufklärung der explanatorischen Variablen kann es bisweilen vorkommen, dass die Modelle nicht sehr stabil sind und dass die voreingestellte Varianzaufklärung des Gesamtmodells von R2 = .99 nicht erreicht wird.
Mögliche Lösungen:
- Kein Einbezug der explanatorischen Variable: Setzen Sie in 'prepareData' oder 'rankByGroup' den Parameter 'group = FALSE'. Die Daten werden dann direkt in Normwerte umgewandelt. Zur Erstellung von Normtabellen können Sie dennoch normal weitermachen, ein Modell erstellen und die Tabellen generieren.
- Vermeiden Sie Modelle mit der maximalen Anzahl an Prädiktoren. Geben Sie in der Funktion 'bestModel' feste Werte für R2 oder die Anzahl an Termen an. Eine günstige Anzahl an Termen können Sie mittels der Funktion 'plotSubset' ermitteln. Suchen Sie wie bei einem Scree-Plot nach dem Knick in der Kurve, ab dem eine weitere Hinzunahme an Prädiktoren nicht mehr zu einer großen Verbesserung der Modellpassung führt. Alternativ können Sie auf die Funktion zur Kreuzvalidierung 'cnorm.cv' zurückgreifen. In jedem Fall ist es sinnvoll, die Modellpassung visuell mittels 'plotPercentiles' bzw. 'plotPercentileSeries' zu inspizieren.
5. Stark mäandernde Perzentillinien in der Funktion 'plotPercentiles'
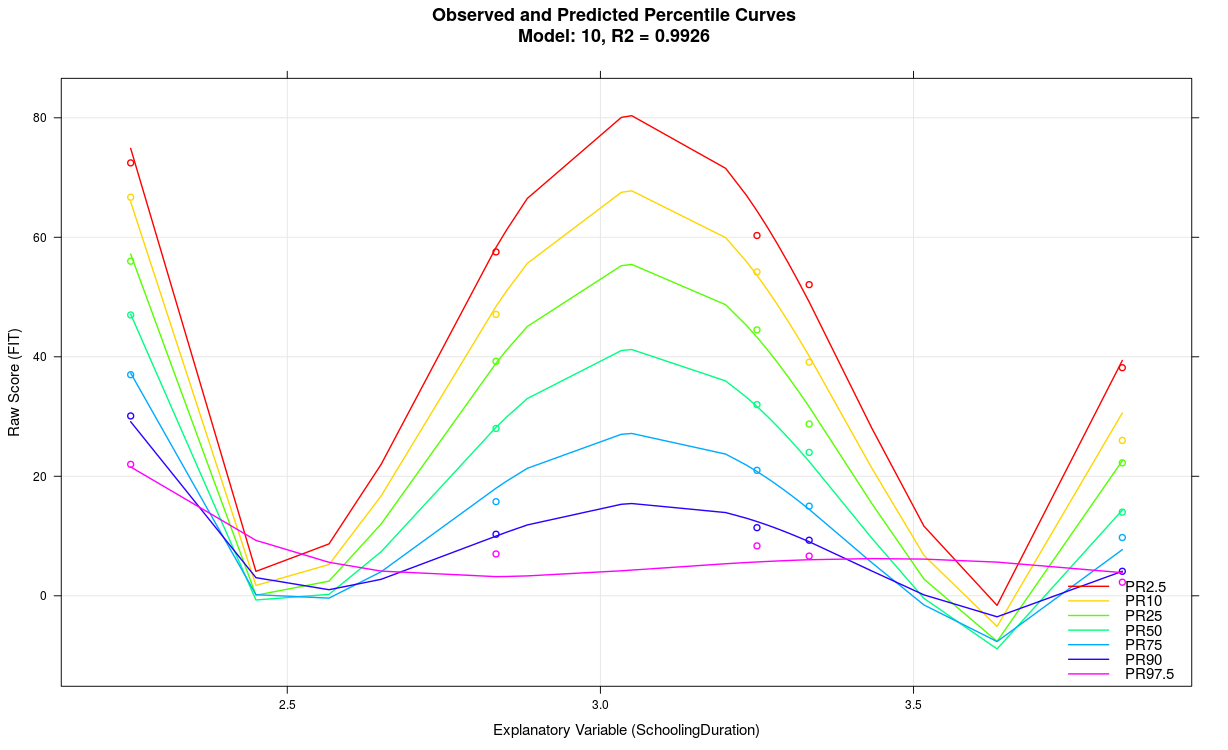
Das Modell weist wahrscheinlich einen Overfit auf, z. B. weil die Varianzaufklärung der explanatorischen Variable nicht sehr hoch ist, zu viele Prädiktoren verwendet wurden, die Skala generell nicht reliabel misst, starke Verletzungen der Repräsentativität in einzelnen Normgruppen vorliegen, usw... Meist ist es die Folge zu kleiner Fallzahlen in den Stichproben, wie z. B. im obigen Beispiel mit n ≤ 50. Möglicherweise kommt das cNORM-Package im konkreten Fall auch an die Grenze seiner Leistungsfähigkeit. Bitte beachten Sie die Lösungsvorschläge des vorangegangenen Punktes. Meist empfiehlt es sich, ein einfacher strukturiertes Modell mit weniger Termen zu verwenden.
Mögliche Lösungen:
- Reduzieren Sie den k-Parameter auf 3 oder sogar 2.
- Reduziern Sie die Anzahl an Termen
- Prüfen Sie Ihre Daten: Rechen die Stichprobengrößen aus? Gibt es in den Daten einen klaren Trend der explanatorischen Variablen?
Reuziert man im obigen Beispiel den k-Parameter auf k=3, ergibt sich folgendes Model:
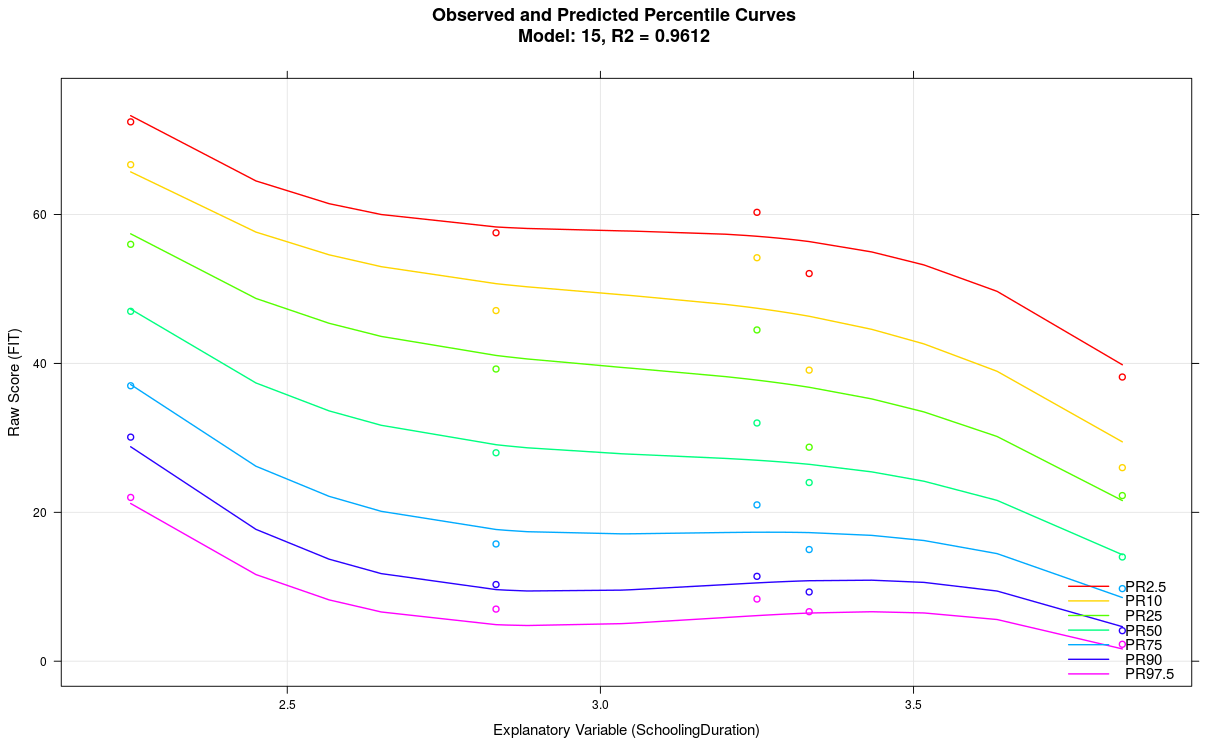
6. Modellierung einer kontinuierlichen Altersvariablen klappt nicht
Wenn Sie für die Datenvorbereitung die Funktion 'prepareData' verwenden und dabei sowohl eine Gruppierungsvariable, eine kontinuierliche Altersvariable als auch die Breite des Altersfensters (Parameter 'width') angeben, dann wird das Ranking mittels eines gleitenden Fensters vorgenommen. Sie können stattdessen auch die Funktion 'rankBySlidingWindow' und anschließend 'computePowers' verwenden. Damit die Modellierung funktionieren kann, muss allerdings die Gruppierungs- mit der Altersvariablen korrespondieren. Das bedeutet: Die Werte der Gruppierungsvariablen sollten das mittlere Alter der jeweiligen Altersgruppe wiederspiegeln.
Mögliche Lösungen:
- Überprüfen Sie das mittlere Alter der Altersgruppen. Entspricht dieses mittlere Alter für jede Person in den Daten der ihr zugewiesenen Gruppierungsvariable?
- Die Funktion 'rankBySlidingWindow' legt eine entsprechende Gruppierungsvariable an, sofern Sie über den Parameter 'nGroups' die Anzahl an Gruppen spezifizieren. Diese spezifiziert bereits den Altersdurchschnitt in den jeweiligen Gruppen.
# Erzeugung einer konsistenten Gruppierungsvariable mit
# beispielsweise 4 Gruppen auf der Basis des Altersdata1 <- rankBySlidingWindow(data, age=data$age, width = 1, nGroups = 4)
7. Können Fälle der Normierungsstichprobe gewichtet werden?
Sowohl beim Ranking als auch in der Modellberechnung mit 'bestModel' kann mit dem Parameter 'weights' eine Gewichtung der Fälle vorgenommen werden. cNORM beinhaltet mit computeWeights() eine Funktion zur Post-Stratifikation der Daten auf der Basis von Raking. Hierdurch kann der Effekt unbalancierter Normstichproben reduziert werden. Bitte beachten Sie hierzu die Vignette "Weighted regression".
 |
Jamovi |
Überblick |
 |